A while back, when I wore my product hat, I started referring to the product backlog as an option backlog. We had lots of ideas going in there, but they were basically stories that we didn’t commit to implementing. Instead, we could pick from our options based on our understanding of the market, our capabilities and so on. Only when we decided to actually them, we committed.
While this perspective moved us forward in an uncharted country, it wasn’t enough. In this process, our options still rely on (the often implicit assumption) that we know what we’re doing. That means that the story has value. That story option 1 is clearly better than story option 2. If we’re wrong, we’ll commit and implement story 1, which we’ll find was wasteful (and may come with other side effect thanks to complexity).
Having options is good, but it’s not enough. We need to have a mechanism to pick the right options. We need to make better decisions.
In Cynefin’s Complex domain, we do probe-sense-respond. In other words, in the Complex domain, where things are uncertain, and there are no proven practices, we probe first – do a small experiment, sense – observe the result, and respond. In Lean Start-Up language we call it Build-Measure-Learn where we Build an MVP – Not the whole software, but enough to validate or invalidate our assumptions.
The more murky the water, the more experiments we need to do in order to learn. In addition, while we’re learning, we would like these experiments not to bankrupt us. I mean, learning is nice, but we still need money to pivot if we reached a dead-end.
Stories out, Hypotheses in
If we are willing to admit to our ignorance, it makes sense to change the way we work. Instead of a product backlog we need a hypothesis backlog. These hypotheses need to be tested, and we need to make more informed decisions at the right cost.
Enter the Lean Learning Board.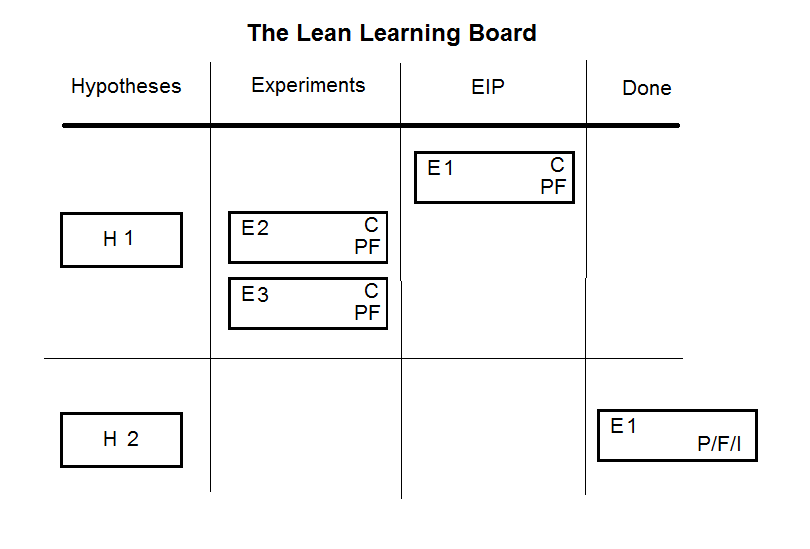
Let’s see how it works:
- Everyone can add a hypothesis to the backlog.
- Hypotheses should be prioritized. Since we’re dealing with risks, we need to test the riskier hypotheses first.
- Once we have hypotheses to validate, we should think of experiments to test them. We can think of different options for experiments that can prove or disprove them.
- Each experiment has associated cost for it. (C on the card) This a #NoEstimates estimate – for example, fits in a sprints or not. Don’t give it more than a few minutes (tops!) thought. If the hypothesis is that important to prove or disprove, the cost should not really matter.
- Every experiment includes a measureable results we expect to have happened – both a definition of success (validation) and failure (PF on the card).
- We then select the experiment we want to conduct. The rule of thumb is to do the most learning at the cheapest cost (and therefore risk).
- An experiment can succeed, fail, result in inconclusive result (P/F/I). It also might pop other questions into our mind (and backlog). If we got a definite answer, we can move to the next hypothesis.
- If we don’t have a definite answers we have options: We can select another experiment to perform to re-validate our hypothesis, since we already have some in our experiment backlog.
- Or maybe we’ve learned enough to reprioritize the hypotheses and we can move on to the next, riskier one.
There you have it: A visual kanban board that tracks learning.
If you’re familiar with Popcorn Flow this model shouldn’t surprise you. I’m breaking down hypotheses to experiments, and weighing those according to their risk and value. (Thank you Claudio for the inspiration!)
3 comments on “The Lean Learning Board”